ISMIR 2020: disentanglement, lottery tickets & NLP meet MIR
As my first experience of ISMIR has just come to an end, I’ve decided to consolidate some of the notes I’ve taken during the week and make them available through this (incomplete) summary of the papers and discussions that stuck out to me the most. With a total of 115 papers, 27 late-breaking/demo abstracts, and another 17 papers presented at the satellite workshop NLP for Music and Audio (NLP4MusA), anyone at the conference will have had a hard time deciding which sessions to attend. My experience was no exception, so in the rest of this post I focus on just the top 3 papers that caught my attention throughout the week, give a quick overview of other interesting discussions and work I’ve come across and highligh some of the thematic trends that seem to have surfaced this year.
If you want to delve deeper into all the work presented at the conference, the full list of papers is available on the website and there are also some excellent blog posts out there giving different and insightful perspectives, like this one by Jordi Pons, this by Hao Hao Tan and this by Philip Tovstogan.
Personal highlights from the poster sessions
Metric Learning vs Classification for Disentangled Music Representation Learning
(J. Lee, N. J. Bryan, J. Salomon, Z. Jin, J. Nam)
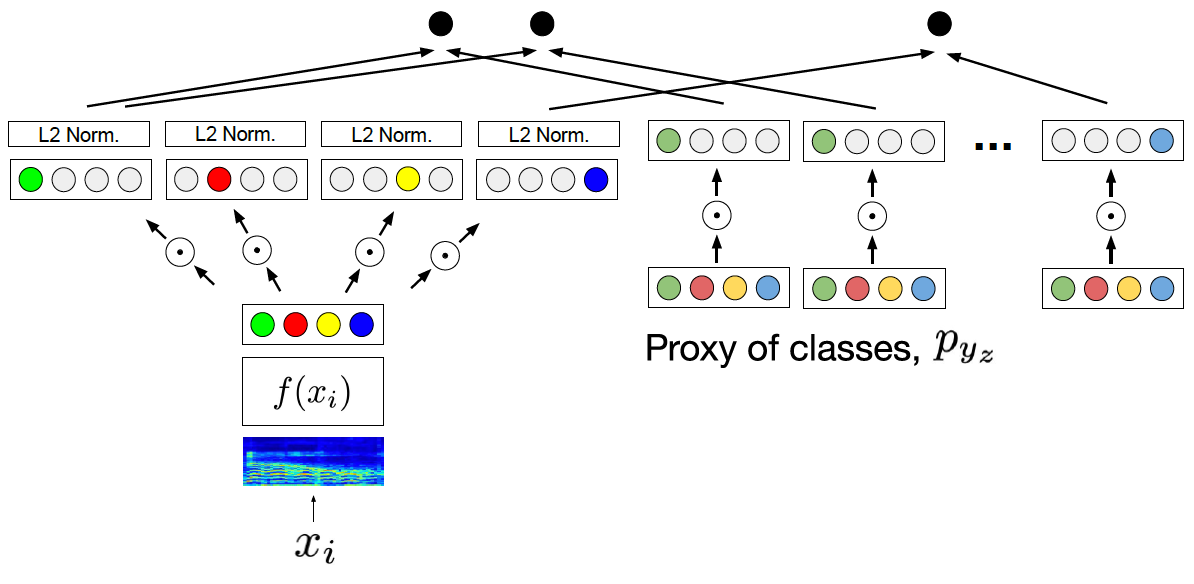
Building upon previous work on disentangled metric learning presented at ICASSP this year (which I had previously reviewed here), this work sets a new milestone in the path towards more generalisable and disentangled representations in MIR. Although usually applied to vastly different tasks, metric learning and classification have been shown before to be, at least under certain conditions, two sides of the same coin. This paper presents experiments demonstrating this underlying link between the two learning frameworks in the music domain, extending the parallel to the case of multi-label classification. It also explores disentangled representation learning using the musical notions of genre, mood, instrument and tempo as factors of variation and examines this through the lenses of triplet-based, proxy-based and classification-based models, showing that the latter, when boosted by disentanglement and normalisation of the embedding feature space, provides the most powerful performance on all but the triplet prediction task.
Ultra-light Deep MIR by Trimming Lottery Tickets
(P. Esling, T. Bazin, A. Bitton, T. J. J. Carsault, N. Devis)
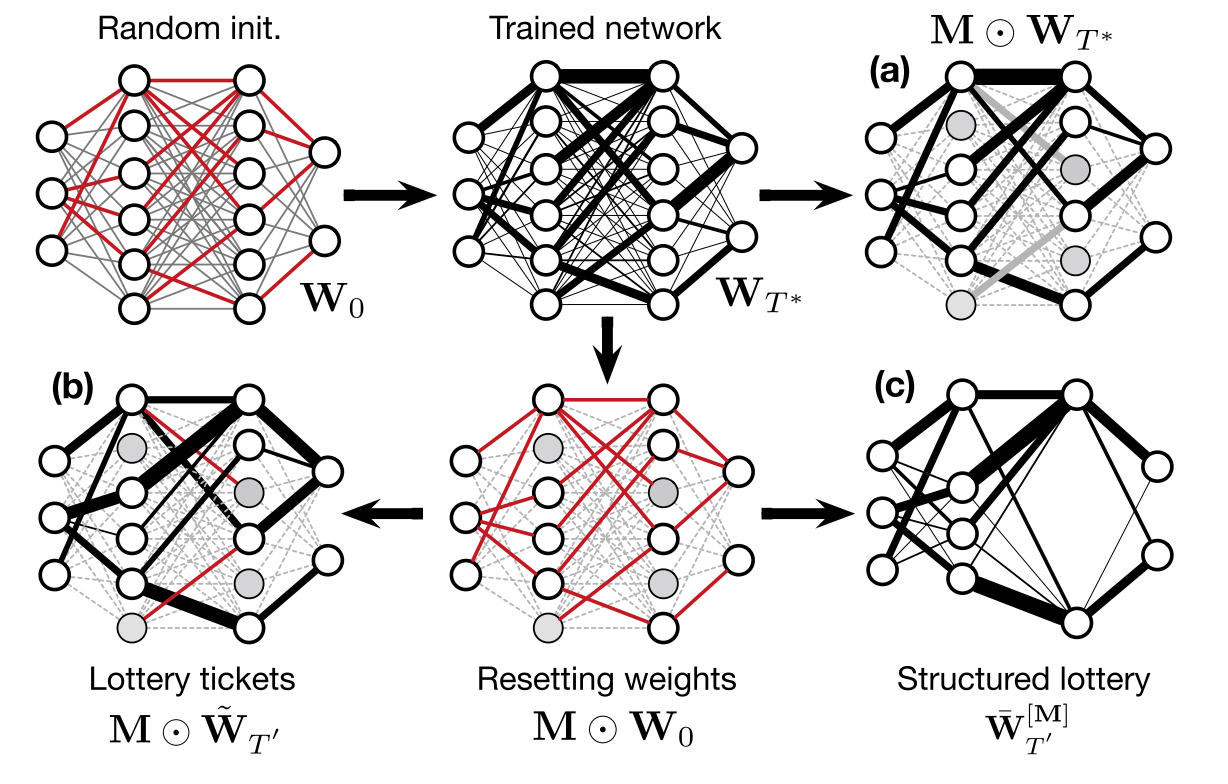
Perhaps unique in its attempt to bring low-power deep learning models to the MIR table (I struggle to recall significant previous efforts in this direction), this paper presents an approach, based on the lottery ticket hypothesis, to find subnetworks that boast both smaller size and shorter inference time than their full-scale counterparts, but still yield a similar accuracy on various tasks such as instrument and singing voice classification, pitch recognition, automatic chord extraction, drum transcription and onset estimation. The key insight is to replace the masking operation of the standard lottery ticket method (which effectively retains the size of the original network) with a structured weight pruning approach, in which successive training iterations become increasingly lighter. The promising results, showing little to no loss in accuracy for models pruned by up to 90%, open up the intriguing prospect of integrating MIR models in embedded audio devices.
Semantically Meaningful Attributes from Co-listen Embeddings for Playlist Exploration and Expansion
(A. Patwari, N. Kong, J. Wang, U. Gargi, M. Covell, A. Jansen)
Another study that builds on previous work presented at ICASSP 2020, this caught my attention for its joint use of audio and co-listen data to address the issue of labelling music with appropriate and semantically meaningful attributes, in a way that mirrors how listeners might actively search for music and curate collections. Music metadata is inconsistent at the best of times and often completely missing when it comes to attributes for which no unanimous definition exists, like those examined here (genre, valence, vocalness, energy and temporal consistency of energy across a track). It is then crucial to be able to infer such attributes through other means.
The approach followed in this work is interesting for a few reasons: audio embeddings obtained from a triplet loss network designed to fit a co-listen graph are repurposed as input features to shallow classification and regression models, which is helpful in giving a tangible demonstration of how large-scale training can serve as a re-usable component for multiple downstream tasks; then these audio embeddings are mapped to a lower-dimensional space of attribute embeddings where similarity more closely relates to human judgement; lastly, the paper proposes a human-in-the-loop approach to playlist curation, in which algorithmic candidates are sampled from the attribute embedding space providing, the authors argue, more easily interpretable recommendations than standard audio-based embeddings.
Perceptually-motivated music generation
Not exactly unheard of before, but a clear trend from this year’s ISMIR nonetheless, the perceptually-motivated music research theme has seen a string of interesting work presented at the conference, confirming that the idea of infusing music generation networks with high-level, intuitive control is really catching on. Here are all those I could spot:
-
Music Fadernets: Controllable Music Generation Based on High-level Features via Low-level Feature Modelling (H. H. Tan, D. Herremans)
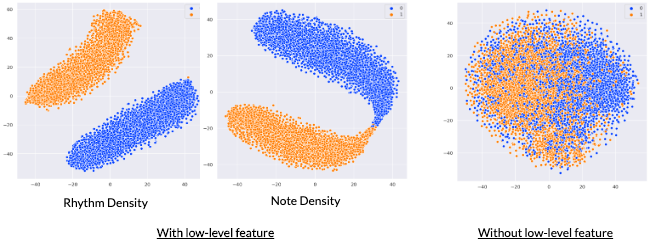
-
Music Sketchnet: Controllable Music Generation via Factorized Representations of Pitch and Rhythm (K. Chen, C. Wang, T. Berg-Kirkpatrick, S. Dubnov)
-
Drumgan: Synthesis of Drum Sounds with Timbral Feature Conditioning Using Generative Adversarial Networks (J. Nistal, S. Lattner, G. Richard)
-
Learning Interpretable Representation for Controllable Polyphonic Music Generation (Z. Wang, D. Wang, Y. Zhang, G. Xia)
-
Attributes-aware Deep Music Transformation (L. Kawai, P. Esling, T. Harada)
NLP4MusA & other multimodal learning
Given my research interest in multimodal learning for music, the NLP for Music and Audio workshop was easily one of my highlights of the week. The first effort to bridge together two research areas that have rarely talked to each other before, the workshop, organised by a committee chaired by Sergio Oramas, brought together researchers with a shared interest for NLP and MIR, mostly manifesting itself in two flavours: one attempting to jointly answer questions about language and music (e.g. lyrics understanding and generation, music description and recommendation) and the other trying to learn from the recent successes in the NLP field and borrow techniques from it (e.g. generation of symbolic music sequences, sequential attention for music relations, melody segmentation).
Aside from the workshop, multimodal learning wasn’t a particularly prominent topic, with only a handful of papers going in this direction. Among these: Towards Multimodal MIR: Predicting Individual Differences from Music-induced Movement (Y. Agrawal et al.), which examines to what extent music-induced movements can help predict personality traits; Score-informed Networks for Music Performance Assessment (J. Huang et al.) which proposes neural network architectures that combine score information with audio recordings to assess music performances; Dance Beat Tracking from Visual Information Alone (F. Pedersoli, M. Goto); Improved Handling of Repeats and Jumps in Audio–sheet Image Synchronization (M. Shan, T. Tsai); and finally a couple on optical music recognition.
Honorable mention: work on electronic music 🎛️
Outside of my direct research area, but well within my personal interests, a small number of papers are also worth mentioning for their contribution to MIR for electronic music. Here’s a list of all those I could spot (hoping I haven’t missed any crucial ones):
-
The Freesound Loop Dataset and Annotation Tool (A. Ramires, F. Font, D. Bogdanov, J. B. L. Smith, Y.-H. Yang, J. Ching, B.-Y. Chen, Y.-K. Wu, H. Wei-Han, X. Serra)
-
A Computational Analysis of Real-world DJ Mixes Using Mix-To-Track Subsequence Alignment (T. Kim, M. Choi, E. Sacks, Y.-H. Yang, J. Nam)
-
Neural Loop Combiner: Neural Network Models for Assessing the Compatibility of Loops (B.-Y. Chen, J. B. L. Smith, Y.-H. Yang)
-
Multidimensional Similarity Modelling of Complex Drum Loops Using the GrooveToolbox (F. Bruford, O. Lartillot, S. McDonald, M. B. Sandler)
Thoughts on the virtual experience
Having had no prior experience of physical academic conferences (welcome to doing a PhD in 2020!), it’s hard for me to truly gauge what I might have missed on. But I can say that, compared to other virtual academic events I attended over the last few months (ICASSP, ICML and various summer schools), ISMIR did deliver the best overall experience, successfully managing to have its typical sense of close-knit community permeate the virtual space within which it unfolded. But part of me can’t help thinking that that same sense of closeness and community that ISMIR has managed to build over the years would hardly be the same today without the physical gatherings it has previously relied on. If, on the one hand, everyone agreed that holding conferences virtually facilitates attendance, lowers barriers to entry and vastly reduces the environmental impact, on the other it can create considerable friction to active participation, particularly for newcomers. So, while next year’s edition will still be online, the decision to experiment with hybrid formats in the future was widely welcomed.